AIがデータアーキテクチャの前提を変える――「集める」から「問う」へのパラダイムシフト
はじめに
「SAP BWをアップグレードしたい」「新しいデータウェアハウスを構築したい」という相談が、今も後を絶ちません。しかし私はこうした議論に対して、⼀度⽴ち⽌まって考えることをお勧めします。AIの登場は、データ基盤の設計思想そのものを根底から変えつつあるからです。
本稿では、従来のデータウェアハウス型アーキテクチャが前提としていた「合理性」を整理し、AIオーケストレーションという新しいパラダイムがその前提をどう覆すかを論じます。あわせて、新パラダイムが抱える課題と、それへの対処についても触れます。
従来のBW/DWHアーキテクチャが解決しようとしていた問題
SAP BWに代表されるデータウェアハウスが⽣まれた背景には、ある時代固有の「制約」がありました。
- ⼈間の認知的な制約
複数の異種システムにまたがるデータを集計するには、エンジニアがSQLやBExクエリを書く必要がありました。⾮エンジニアのビジネスユーザーが⾃⼒でデータを分析することは、事実上不可能でした。 - 技術的な制約
リアルタイムに複数システムを横断してデータを取得し、即座に集計・可視化する仕組みを実現するコストは膨⼤でした。データを⼀箇所に「引っ張ってきておく」ことが、現実的な唯一の選択肢でした。 - 設計上の制約
どの軸で分析するかを事前にディメンションとして定義し、スタースキーマやInfoCubeを設計することが必要でした。事前に想定していない切り⼝での分析は、追加の開発なしには実現できませんでした。
上記のようにBWは、【「⼈間がデータと対話できない」という問題への、当時の最善解】だったわけです。データを⼀元管理し、事前に集計・構造化しておくことで、ユーザーが扱いやすい形に変換する。これは合理的な設計でした。しかしその合理性は、あくまで当時の技術的・認知的制約に基づくものだったと⾔えるでしょう。
AIフロントの登場が変えたこと
⼤規模⾔語モデル(LLM)とMCP(Model Context Protocol)のようなツール連携技術の普及により、データアーキテクチャの根本的な前提が変わりました。
「データの意味を理解できる存在」がフロントに⽴ったのです。
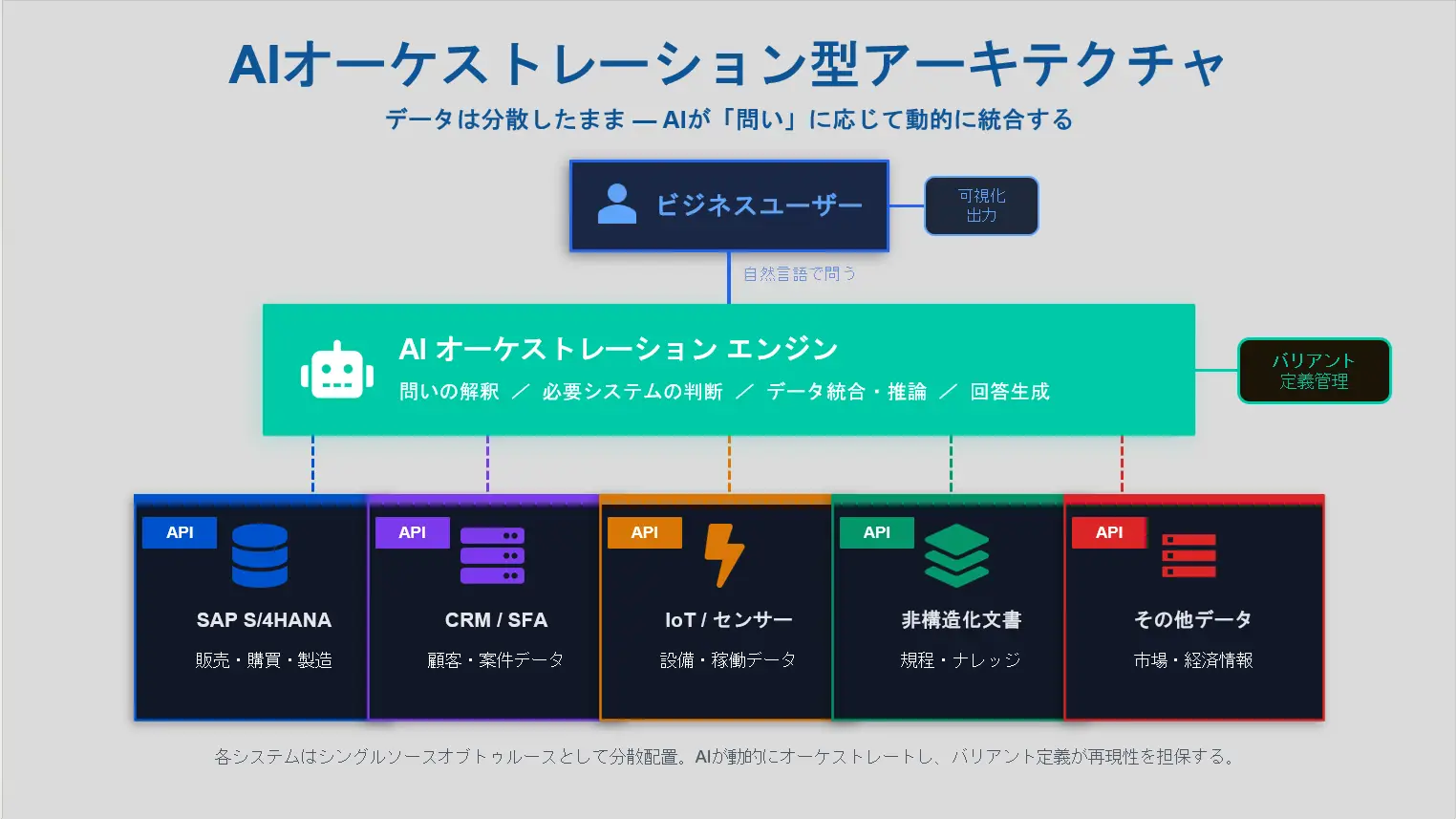
これは何を意味するのか。データが分散していても、スキーマが異なっていても、構造化・⾮構造化の別を問わず、AIが横断的に解釈・統合できるようになりました。各システムがAPIを公開しているだけで⼗分で、AIが必要なタイミングで必要なシステムに問い合わせ、結果を統合して返す。これは従来のBWが担っていた「事前集約」という役割を、オンデマンドの「動的統合」に置き換えるものです。
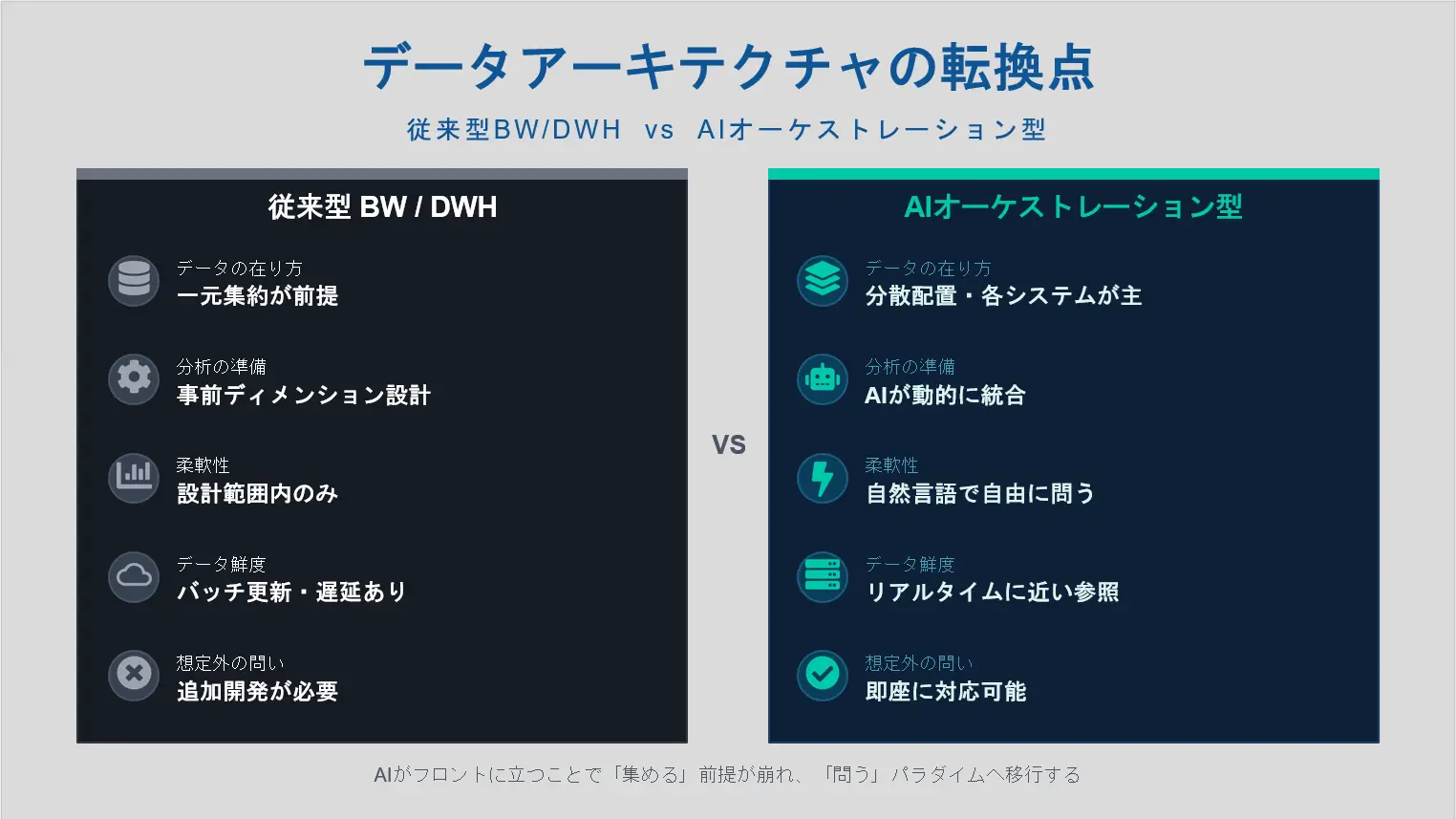
この変化を整理すると次のようになります。
| 観点 | 従来型BW/DWH | AIオーケストレーション型 |
| データの配置 | ⼀元集約が前提 | 分散したまま保持 |
| 分析の準備 | 事前のディメンション設計が必要 | 問いに応じて動的に構成 |
| ユーザーインターフェース | BIツール(GUI操作) | ⾃然⾔語 |
| 対応の柔軟性 | 事前設計の範囲内 | 臨機応変な問いに対応 |
| データの鮮度 | バッチ更新による遅延 | リアルタイムに近い参照 |
特に「データの鮮度」は重要な点です。BWのバッチ処理では数時間〜1⽇の時間差が⽣じることが⼀般的でしたが、AIがAPIを直接呼び出すことで、ほぼリアルタイムの情報を基に分析・回答が可能になります。
RAGの位置づけの変化
AI利⽤が広まったばかりの頃には、企業固有の知識をLLMに持たせるためにRAG(Retrieval Augmented Generation)の構築が広く提唱されました。しかし近年、「RAGに頼らずとも良い」という議論が起きています。その背景にはいくつかの変化がありました。コンテキストウィンドウの⼤幅拡⼤により、ドキュメント全体を⼀度に渡せるようになったこと、モデルの⻑⽂理解精度が向上したこと、そしてMCPのようなツール呼び出しによるリアルタイムアクセスが普及したことです。
もっともRAGが完全に不要になるわけではありません。数万件を超える⾮構造化ドキュメントから必要な情報を効率よく絞り込む局⾯では、ベクトル検索は依然として有効です。ポイントは、RAGは「⼤量⽂書の絞り込み技術」として位置づけ直され、「企業知識の統合⼿段」としての役割は後退しつつあるということです。
新パラダイムの最⼤の課題︓再現性の確⽴
AIオーケストレーション型のアーキテクチャには、⼤きなアキレス腱があります。それが再現性の問題です。
「先⽉の売上を⾒せて」という問いに対して、AIが「先⽉」をどう解釈するか、どのシステムのどのテーブルを参照するか、棒グラフにするか折れ線にするか——これらは全て推論に委ねられます。複数⼈が同じ質問をしても、微妙に異なる結果が返ってくる可能性があります。従来のBIツールが担っていた「再現性の保証」は、実はツール側が暗黙的に担っていたものでした。同じレポートを開けば同じ定義で同じ集計が⾛る。この当たり前の前提が、AIオーケストレーション型では⾃然には成⽴しないのです。
この問題への対処として有効なのが、「バリアント化」という発想です。 重要なKPIや定型分析については、「何を・どの範囲で・どのように⾒せるか」をテンプレートとして事前に定義しておくのです。ユーザーはバリアントを選び、期間やコードなどのパラメータだけを変えれば良い。⾃然⾔語の柔軟性を保ちながらも、重要な判断基準・表現形式・集計ロジックは明⽰的に管理する。これにより、アドホックな分析と定型再現性を両⽴させることができます。
企業での利⽤を想定すると、当然ながら複数⼈が同時に使える環境の設計も⽋かせません。この点でも、従来のBIツールが内蔵していた機能を、AIオーケストレーション型では別途設計する必要があります。 具体的には、バリアント定義をチームで共有できるリポジトリとして管理すること、誰がいつどのバリアントを実行したかの履歴を残すこと、出⼒結果をスナップショットとして保存・共有できること、そして権限によって参照できるデータ範囲を制御すること、といった要件が出てきます。
残る課題︓コストとガバナンス
AIオーケストレーション型への移⾏には、他にもコストとレイテンシといった現実的に検討すべき課題が残ります。事前集計による⾼速なクエリ応答に慣れた環境では、LLMの推論コストやAPIコール数との向き合い⽅を設計する必要があります。⼤規模な定型レポート業務については、依然として事前集計の合理性が残る場合もあります。
また、データガバナンスの観点では、⼀元管理されていないデータに対するアクセス制御・監査ログ・マスタデータ管理をどう担保するかが、新たな設計課題となります。
ITコンサルタントとしての提⾔
「BWのアップグレードをしたい」という相談を受けた際、私はまず問い直します。「そのBWは何のために存在しているのですか」と。 もしその答えが「各部⾨がデータを⾒るため」「KPIを定期的にモニタリングするため」であれば、今まさにそのアーキテクチャを再考すべきタイミングです。AIオーケストレーションへの移⾏は、BWの廃⽌ではなく、データ基盤の設計思想の転換を意味します。
新しいアーキテクチャが⽬指す姿は、こうです。データは各システムがシングルソースオブトゥルースとして保持し、AIがオーケストレーション層として必要なデータを動的に統合する。⼈間はデータの構造を設計するのではなく、「何を知りたいか」を設計する。重要なKPIはバリアントとして明⽰的に管理し、再現性とガバナンスを確保する。
今まさにBWやDWHへの投資判断を迫られている企業は、⼀度このパラダイムシフトを踏まえた上で、投資の⽅向性を⾒直すことを強くお勧めします。
これは「あるべき思想への回帰」でもある
最後に、より本質的な視点を⼀つ加えたいと思います。
従来のBWやBI開発では、「何を知りたいか」という本来の問いが、InfoCubeの設計・データマッピング・クエリのコーディングといった技術的作業の中で徐々に薄れていく構造がありました。開発者は仕様通りに動くものを作ることに集中せざるを得ず、発注者側も技術的制約に引っ張られ「できる範囲で要件を考える」ようになる。本来の⽬的から設計が離れていく、という逆転現象が起きやすかったと言えるでしょう。
新しいアーキテクチャにおけるKPIやロジックの定義設計は、その技術的な翻訳コストがほぼ消えるため、「なぜこの数字が必要なのか」「この意思決定のために何を⾒るべきか」という問いに素直に向き合える。設計者が、意思決定の⽬的から直接ロジックを書き起こせる距離感になります。
これは単なる効率化ではありません。技術の制約によって本来の⽬的への意識が離れてしまっていた状態から、あるべき思想に⽴ち戻る試みとも⾔えます。データ活⽤の設計が、ビジネスの問いに最も近い場所に戻ってくる。AIによるデータアーキテクチャの転換が持つ意味は、そこまで射程に⼊れて考えるべきだと私は考えています。




お問い合わせください